
Do you already know the types of databases? If you’re a programmer, you need to consider the scope of your developments, and if you’re a marketer or CEO, you want to store and analyze your customers’ behavior to improve your results. It is where the importance of knowing the database types comes into play.
Databases are fundamental to the modern world as there is one behind every platform, website, or application. Therefore, knowledge of BBDD (abbreviation for databases) should be basic knowledge for people who consume and manufacture technology.
So what’s the best database for your company or project? Make yourself a cup of coffee and find out! In today’s article, you will learn what a database is, how it is classified, and what types of databases.
Table of Contents
What is a database?
A database is a set of information creates to store and process information of various types and dimensions. The databases can order or design with different types of architecture depending on the complexity of your information and the purpose.
Database types
Many types of databases focus on specific areas or tasks, and these are the main ones:
Hierarchical databases
It is one of the oldest database types, dating back to the beginnings of logic programming. Hierarchical databases use to manage large volumes of data since their inverted tree structure allows orderly storage and scaling.
These databases are very rigid or challenging to alter; this allows the data to consult in a simple way and assurance the data is not biased.
To do the analysis correctly with this type of database, the person must know its structure through its three types of segments or levels: Parent, child, and root.
The levels of the hierarchical structure are called “height.” Level 0 of a hierarchical database corresponds to the root node and is the highest level in the hierarchy.
Then it follows by the parent node, which can have an unlimited number of child nodes.
Although a child node can only correspond to one parent. The nodes that do not have descendants (children) are called leaves.
Arcs, also known as links, join all nodes. It must be taken into account that between two data sets, there can only be one interrelation.
Also, once the structure of a tree has been established, the hierarchy cannot be modified.
On the other hand, some of the advantages of this type of database are that the navigation is fast.
The structure is easy to understand, allows information to share globally within an organization.
And also, it maintains the integrity of the information and seeks independence from data. However, it can say that a disadvantage is that it is difficult to modify it due to its rigidity.
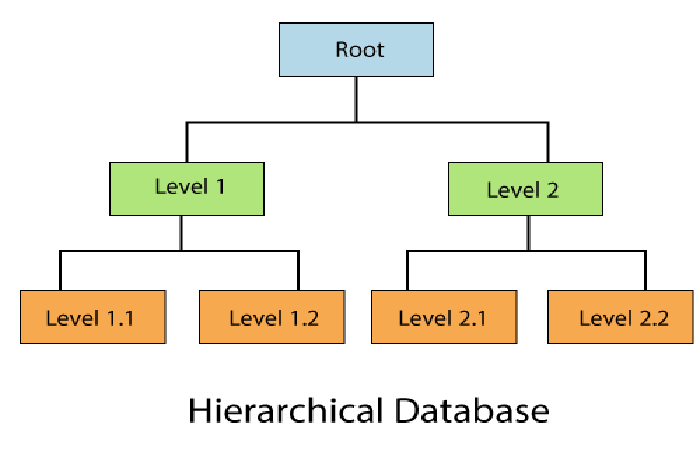
Hierarchical Database Example
These databases use in Big Data Analytics. This can apply in different commercial scenarios: to analyze the behavior of millions of users in a web application, customer segmentation, sales projection, and device optimization bright.
Network databases
Network databases (or “plex structure”), as the name implies, It is a set of data link together that form a kind of network. These nodes can store different types of information and are more efficient than other types of databases since by having several “parent-child” relationships, they are less redundant and integral.
As we have mentioned, these types of databases work on a set basis. These forms base on two kinds of records: parent records, called owners, and child records, called members.
Compared to hierarchical databases, these various relationships through connector sets. In other words, a child record can have multiple parents.
Likewise, different hierarchical levels can establish in a network database.
Network Database Examples
One advantage of this type of database is that many-to-many relationships can exist, which is helpful in an online store.
Relate products with orders and their customers in e-commerce like Amazon, since a product can apply to many orders and many customers who can add several products in the same order.
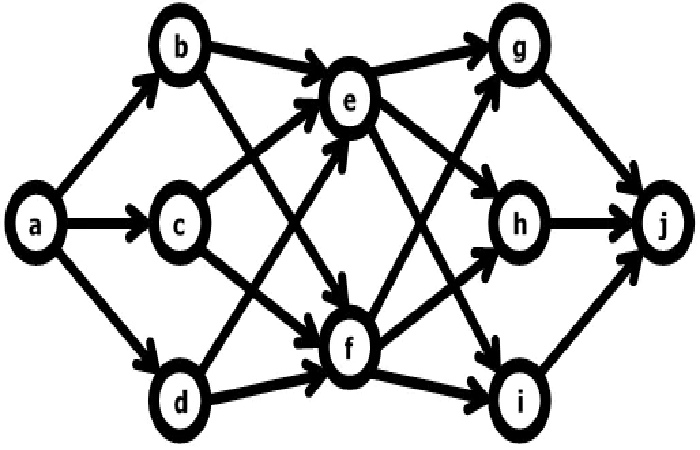
On the other hand, another example of a network database can give in a doctor’s office. A doctor can be related to different patients, related to various drugs, and other doctors.
Deductive databases
Deductive databases can deduce or return new information based on specific parameters using existing data set and applying logical rules. In other words, you make deductions based on inferences.
This type of database is known as a logical database, and it is very complex, as it has a lot to do with mathematics and relational calculus.
In addition, it uses a declarative language, called Datalog, with which the “requests” are made, or the new information deduced consistently from the existing data, taking into account the rules previously established by the language.
Some of the advantages of these types of databases they can support complex elements and sets, allow queries through logical rules with the interpretation of information from the same database, and specialized algorithms can use to optimize queries.
However, it is worth mentioning that a deductive database must design with great care and efficiency. If the logical rules and deduction processes not well define beforehand, the database will likely give inconsistent results or get stuck in infinite loops.
The information search process in these databases is divide into two phases:
Interrogation phase. Here the logical database searches within the implicit deductible information. It’s known as derivation rules.
Modification phase. In this phase, new deductible information add. It’s called generation rules.
Relational databases
Relational databases store information related to each other, allowing access in a more direct way. It base on relational models with values or data living in the records (or cells) that relates to a unique row or tuple ID (which is also known as a primary key) and an attribute given to each column. Many data analysis tools use this type of database.
Data Scientists and professors explain that relational databases allow us to link information to establish references between data. Such as SQL, which is among the top Relational databases, one can enroll themselves in SQL Course for deep knowledge and increase their chance of securing a successful career.
This is the most common and the most used to declare relationships between tables; that is, it establishes a relationship between the tables and how they communicate with each other so that the information organization is more efficient.
Some of the advantages of relational databases are that it allows you to handle large amounts of data, maintaining uniformity in all instances of it; that is, it ensures that all copies of the database have identical information at all times.
Likewise, this type of database avoids duplication of registration and allows several applications to access the same information simultaneously. On the other hand, it simplifies the user experience since it is usually more understandable and easy to apply.
However, in the case of its disadvantages,
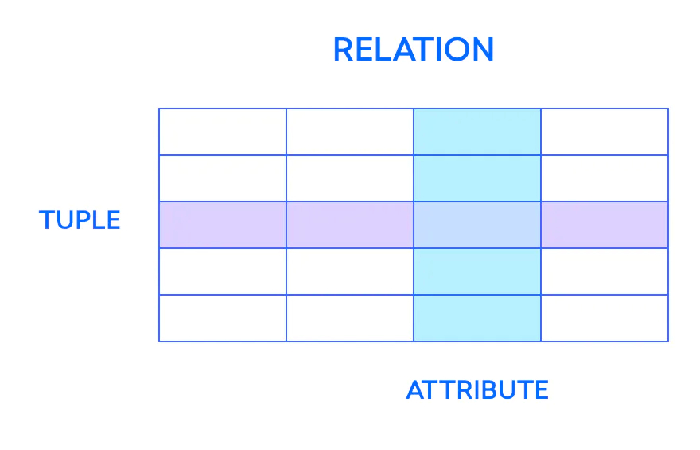
it is worth mentioning that relational databases have difficulties handling graphic and multimedia elements.
They do not allow you to organize the information hierarchically because all the rows are at the same level, and subordinate cells cannot place.
Relational Database Example
A system with records of employees in a company, with which their data, department, etc., can know from their number or employee ID, which allows it to be related to another database in which the data are stored. Salaries of each employee.
Relational databases use in large stores to store information about their customers, orders, and order shipments; in this way, a relationship can establish between these criteria and their most important data.
Non-relational databases
Non-relational or “NoSQL” databases have flexible schemas and allow unstructured data to be stored and manipulated.
The data in these types of databases are unrelated to other data sets. It does not define at the structure level, allowing them to be highly scalable, perform very well, and more profitable.
In simple words, non-relational databases not organize by tables, records, or fields but by documents, allowing them to be highly scalable, more profitable, and high-performance.
It can say that non-relational databases are more current elements than relational databases.
Since they focus on the management of large volumes of data and unstructured or semi-structured information, which generates much more flexibility when creating data schemas.
Non-relational databases are a new information storage system; therefore, it’s not considered a standardized procedure.
Also, compared to the previous type of databases, this one does not use the SQL language for queries but as a support tool.
On the other hand, there are different types of non-relational databases. For example:
Key-value. They are types of databases that are responsible for storing key and value pairs. Each key represents a unique identifier, and each key has a value assigned.
Documents This non-relational database stores documents or objects of a flexible, semi-structured, and hierarchical nature.
Usually, these databases use to store, manage and consult data from content management systems or user profiles.
Graphics. These databases are for creating data relationships between entities and navigating through them. They often use for social networks and fraud prevention systems.
In Memory. They are non-relational databases responsible for storing information, offering answers quickly, and withstanding prominent peaks in traffic.
Non-relational database example
A mobile application where not all products have the same type of descriptions, that is, a bottle of chlorine will have the size of the bottle as a description, but if we look at apples or oranges, they will come by weight in kilos and or units of each fruit.
Multidimensional databases
It is one of the types of databases creates using relational databases, organizing information in tables, but they differ in that the structure of the tables corresponds to information cubes.
Information cubes made up of two elements:
Table of dimensions. Data such as names or dates store here.
The fact table is responsible for storing the values that correspond to the keys of the dimension tables.
The multidimensional database system lives within a “Data Warehouse,” a central information repository of a company where its information is store safely and reliably and efficiently retrieves and manages.
In addition, these types of databases can process information very quickly and work with data with a high level of abstraction, which is ideal for platforms that require automatic or real-time responses.
Many Business Intelligence applications builts that serve for decision-making around the business and Her future. Multidimensional databases use to create OLAP-type applications (“online analytical processing applications”). The graphic form of this concept can see with the “OLAP cube,” in which its different dimensions can observe.
Multidimensional Database Example
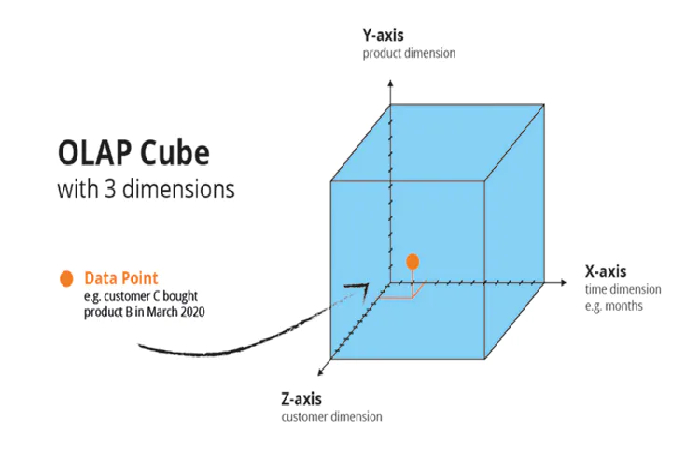
The database of a company in the sales area has three dimensions; the size of the customers and their data, the size of the products and their specifications, and the size of the time in which they made those sales. With this, the company could know what month a specific customer purchased one of its products. And it would look like this:
Object-oriented databases
Object-oriented databases (or object databases) exist to take care of specific needs in object-oriented programming. This type of database is characterizing by grouping data into objects or information packages that have a relationship between them and can easily group without consulting many tables or data sets.
They are similar to relational databases, but object databases work with classes instead of relations, objects instead of tuples or rows, and variables instead of attributes. These databases use in software and hardware applications due to their high data storage and compatibility with many popular programming languages.
These types of databases currently use by organizations that belong to engineering, telecommunications, and molecular biology since they work very well to display complex data. Furthermore, they are easy to use and accessible, as they are open source.
Object-Oriented Database example
An object-oriented database with the information of employees of a company, in which the ‘class’ would be the area of the employee, the ‘object’ would be the name of the employee, and the ‘attributes’ would be the information of the employee as his address or phone.

Distributed databases
Its infrastructure mainly characterizes this type of database.
since it collects various data sets that are physically or logically linked through servers or computers in your communications system.
The distributed databases are easy to access by their administrators, being anywhere, very similar to a local business network.
Distributed databases are nodes that communicate through a communications network, which carries out continuous information transactions. Likewise, they operate independently of their location, equipment, operating system, or network.
Many corporations migrate to information architectures based on distributed databases due to their high performance and high profitability.
You do not have to increase a single server with a giant database.
But rather invest in several servers or smaller computers that maintain their performance.
Distributed database example
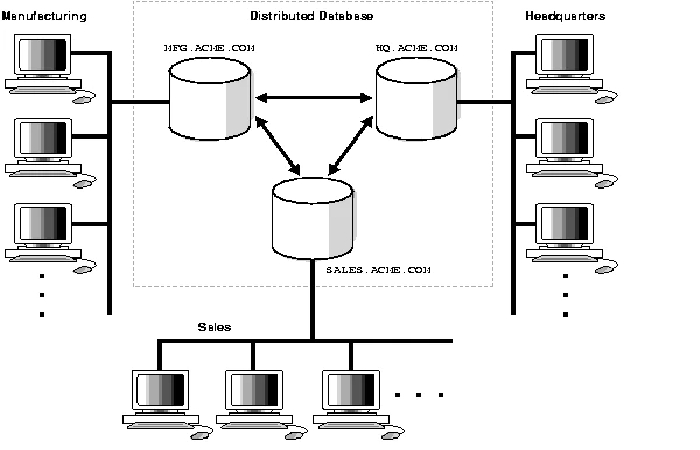
National universities have different locations and need to distribute databases in which the information of all students in store. Still, these servers are located on the other campuses and the university rectory.
Conclusion
We hope today’s article has been helpful! Now you have more idea about what types of databases can help you better store and process your business information. It is on your side to make the best decision and take your company or product to the top.